
关注
关注公众号 小王说安全,搜索icp-mcp领取本页开源代码。

前沿
众所周知,现在的AI 只是一个较大的搜索器,那么肯定不能集成像 某公司 这种 域名备案情况 ,使用网络搜索也是不大可能完全收集的
而备案信息至于在官网 工信部的ICP备案网 上才能获取到最新的(当然其他的平台也有,但是都是从这里爬取的)
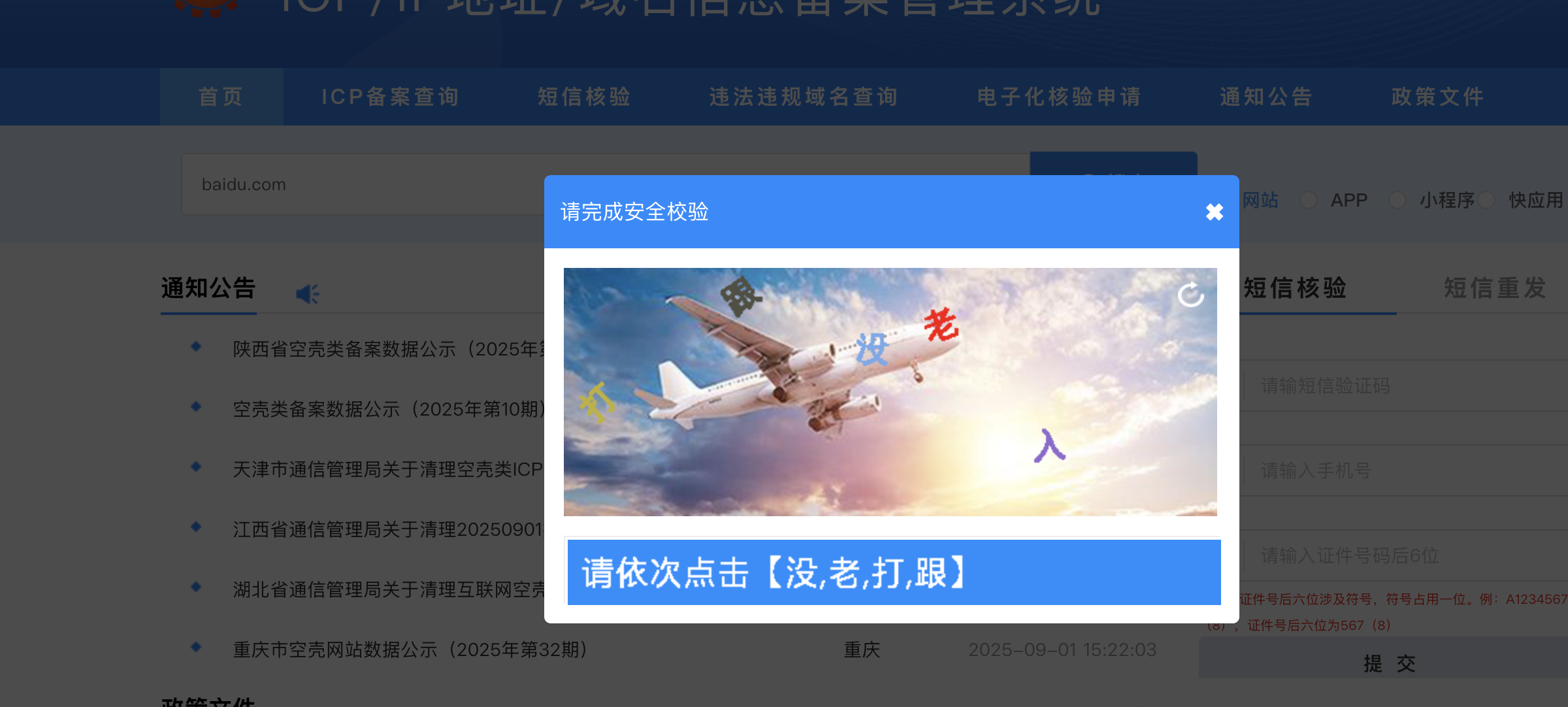
那么有没有一种方式能让这两者结合一下用AI自动调用某公的接口然后,帮我总结、导出所有备案信息呢

有的老弟,当然有的,就是利用mcp服务 ,让AI调用mcp ,mcp在去调用某公的接口,就可以实现了
实现
先去github 找个开源的icp爬虫框架基于模型训练的(这里自己去找吧,关键字就是icp 爬虫),然后通过一顿乱修乱改先把对接icp的搞定

然后写入关键的MCP代码(完整版,已开源,可前往我的公众号,小王说安全,输入icp-mcp 领取)
@mcp.tool()
async def icp_query(keyword: str, page: int = 1) -> dict:
"""查询 ICP 备案信息
参数:
keyword: 查询关键词,可以是公司名、备案号或域名
page: 查询页数
返回:
包含分页信息和备案记录数组
"""
# 首先尝试从数据库缓存中获取查询结果
cached_result = cache_utils.load_query_result_from_cache(keyword, page)
if cached_result:
return cached_result
# 尝试从缓存获取token
token_dict = cache_utils.load_token_from_cache_one()
# 如果缓存中没有有效的token,则重新获取
if not token_dict:
for i in range(0, 5):
try:
token_dict = icp.app.get_uid_token_sign()
except Exception as e:
loguru.logger.error(e)
if i == 4:
return {
'error': e
}
continue
break
# 保存新获取的token到缓存
cache_utils.save_token_to_cache(token_dict)
data = {
"pageNum": page,
"domain": keyword,
'service_type': "1",
"token": token_dict.get('token', ""),
"uuid": token_dict.get('uuid', ''),
"sign": token_dict.get('sign', ''),
'rci': token_dict.get('rci', ""),
}
text = icp.app.query(data)
if text.get('code', 500) != 200:
cache_utils.delete_token_to_cache(token_dict)
loguru.logger.error(text.get('msg', Exception(f"状态码 {text.get('code', 500)}")))
return {
'error': text.get('msg', Exception(f"状态码 {text.get('code', 500)}"))
}
params_list = text.get('params', {}).get('list', [])
if 'rci' in text:
rci = text.get('rci')
token_dict['rci'] = rci
cache_utils.update_token_cache(token_dict)
result = {
"keyword": keyword,
"page": page,
"pageSize": 40,
"total": text.get('params', {}).get('total', 0),
"records": params_list,
}
# 保存查询结果到数据库
cache_utils.save_query_result(keyword, page, result)
# cache_utils.delete_token_to_cache(token_dict)
return result
然后一顿kuku乱造,把环境搭建好
➜ src git:(main) ✗ python3 server.py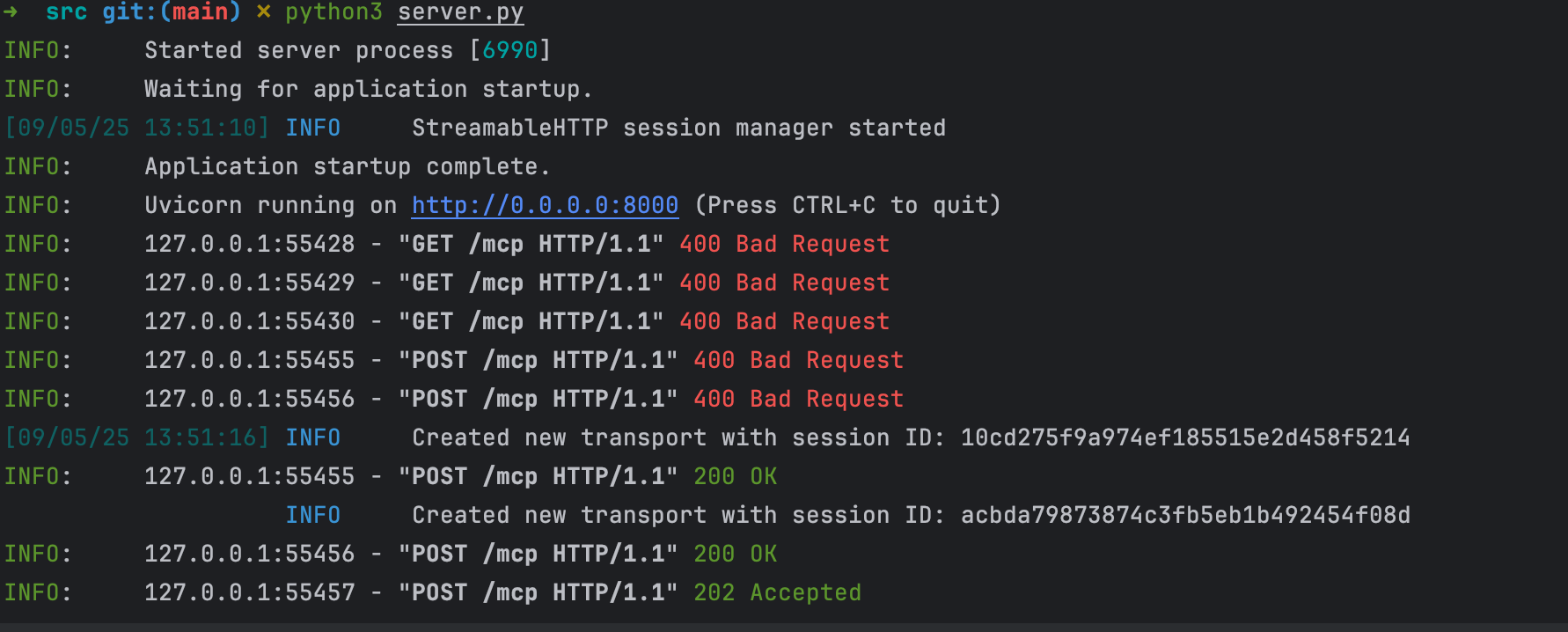
然后导入,mcp客户端,这里我推荐使用Cherry Sudio ,其他的mcp客户端都可以哈
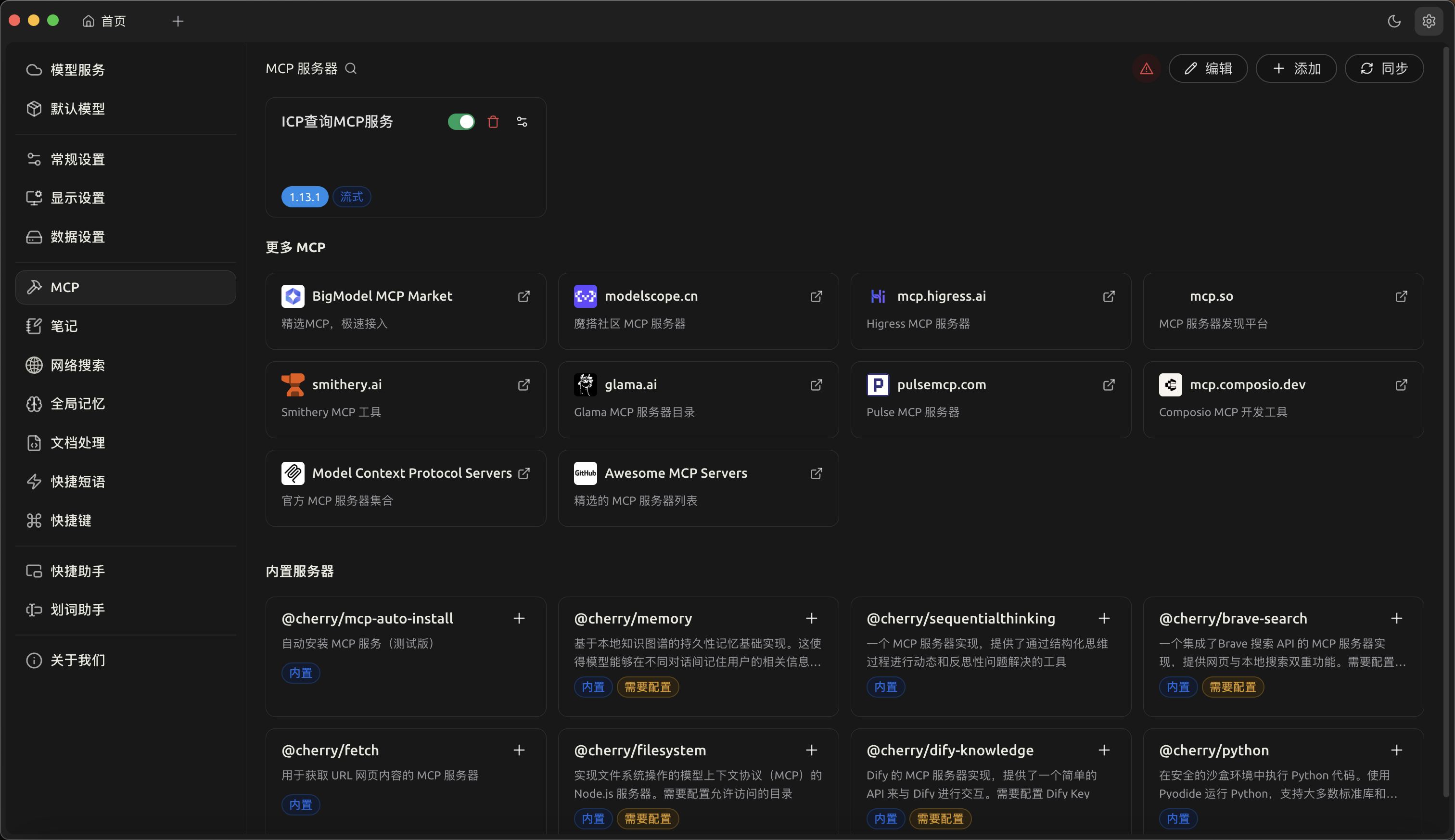
到此准备工作就完全搞定了,然后我们来做一下 前后对比
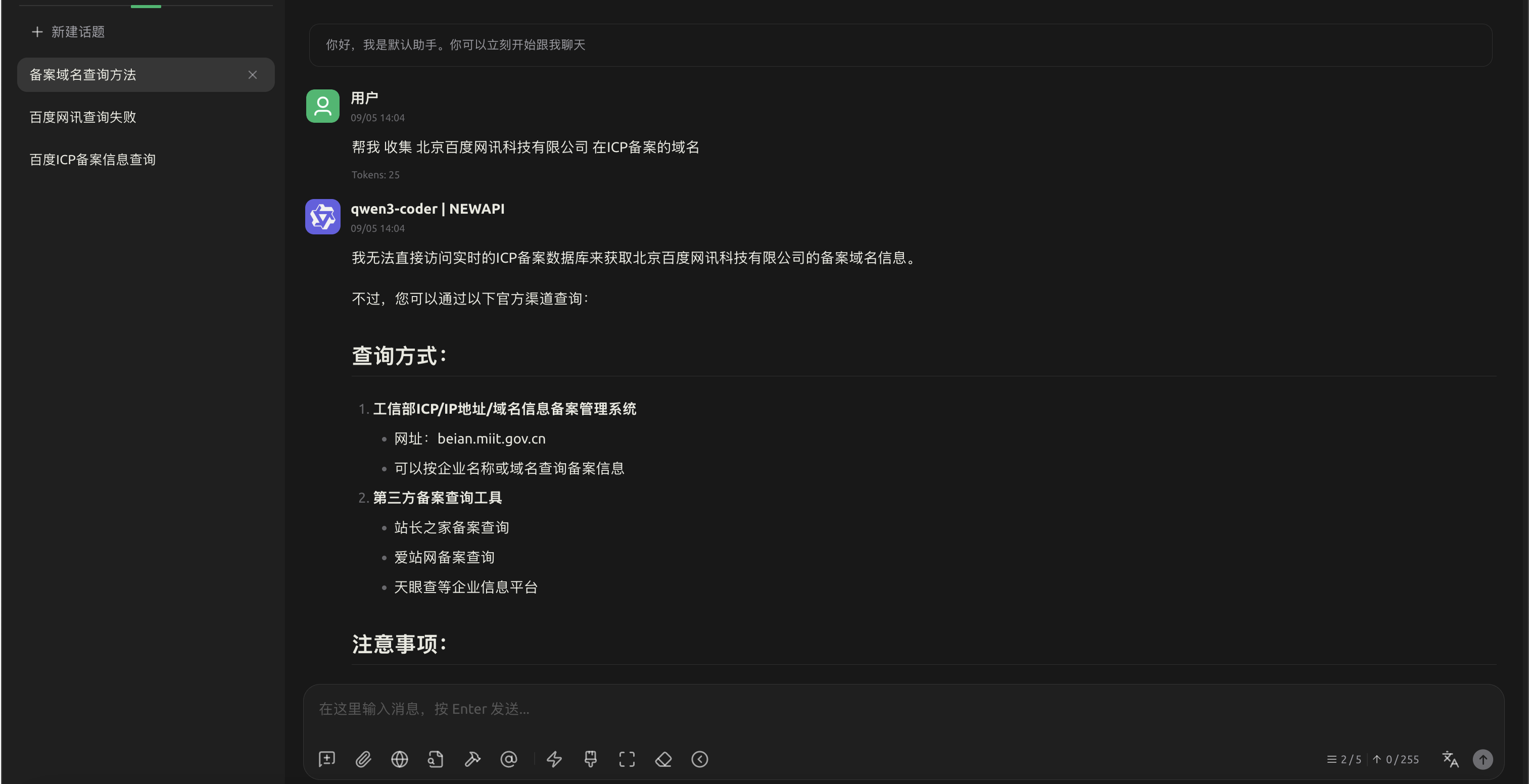
这是未接入icp-mcp的回答
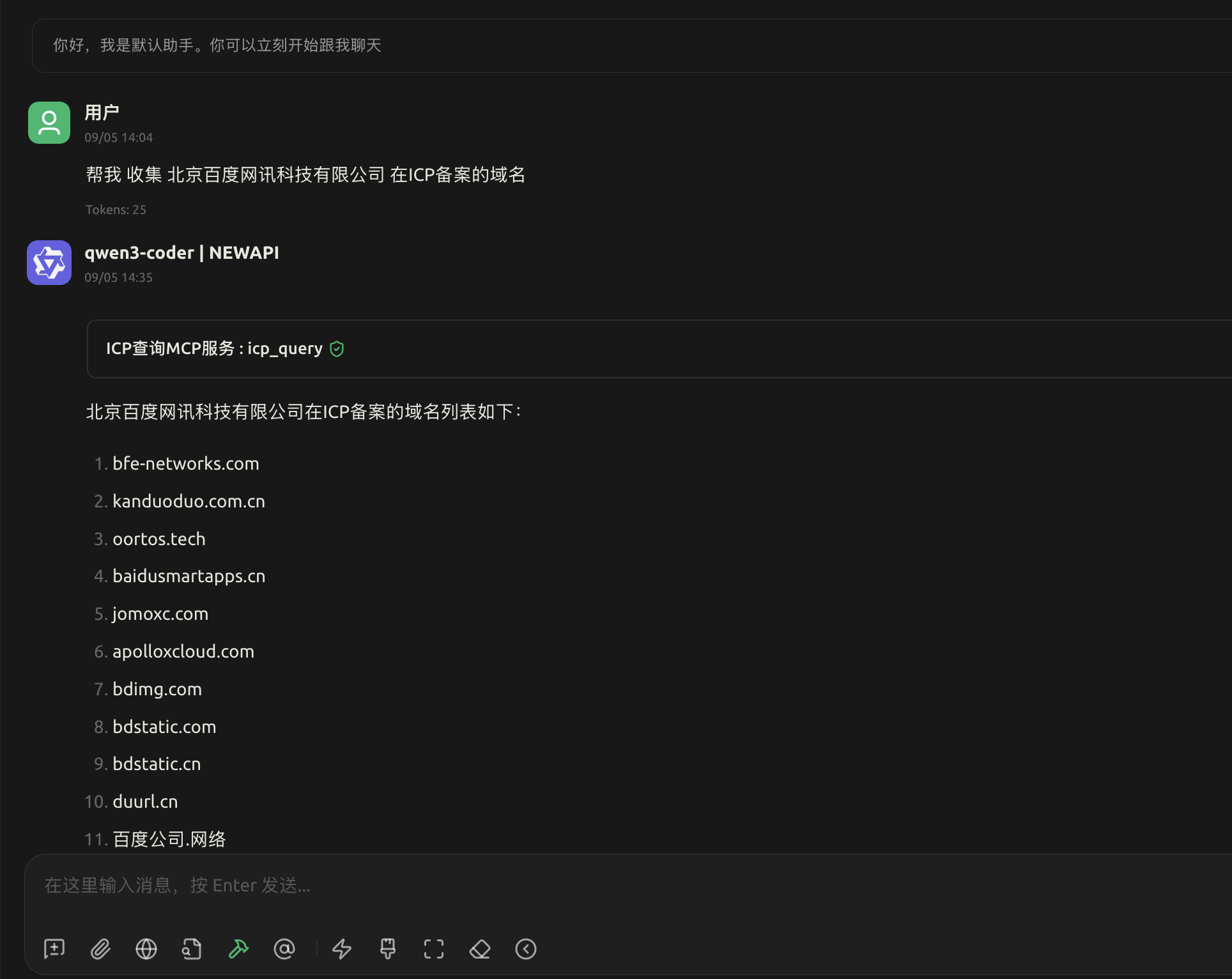
这是接入了icp-mcp的回答
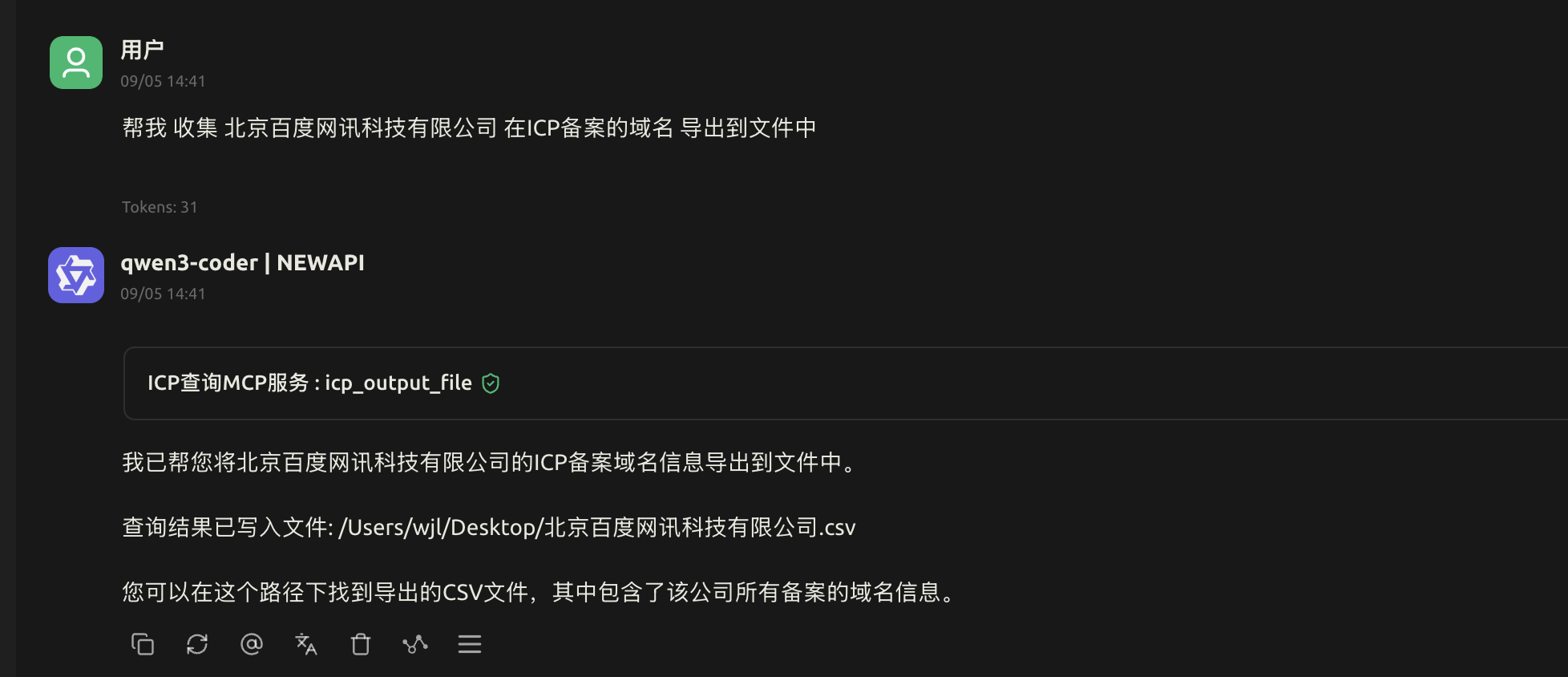
最后我还实现了导出到文件,如果你是本地部署的,那么还可以利用这个导出到文件中
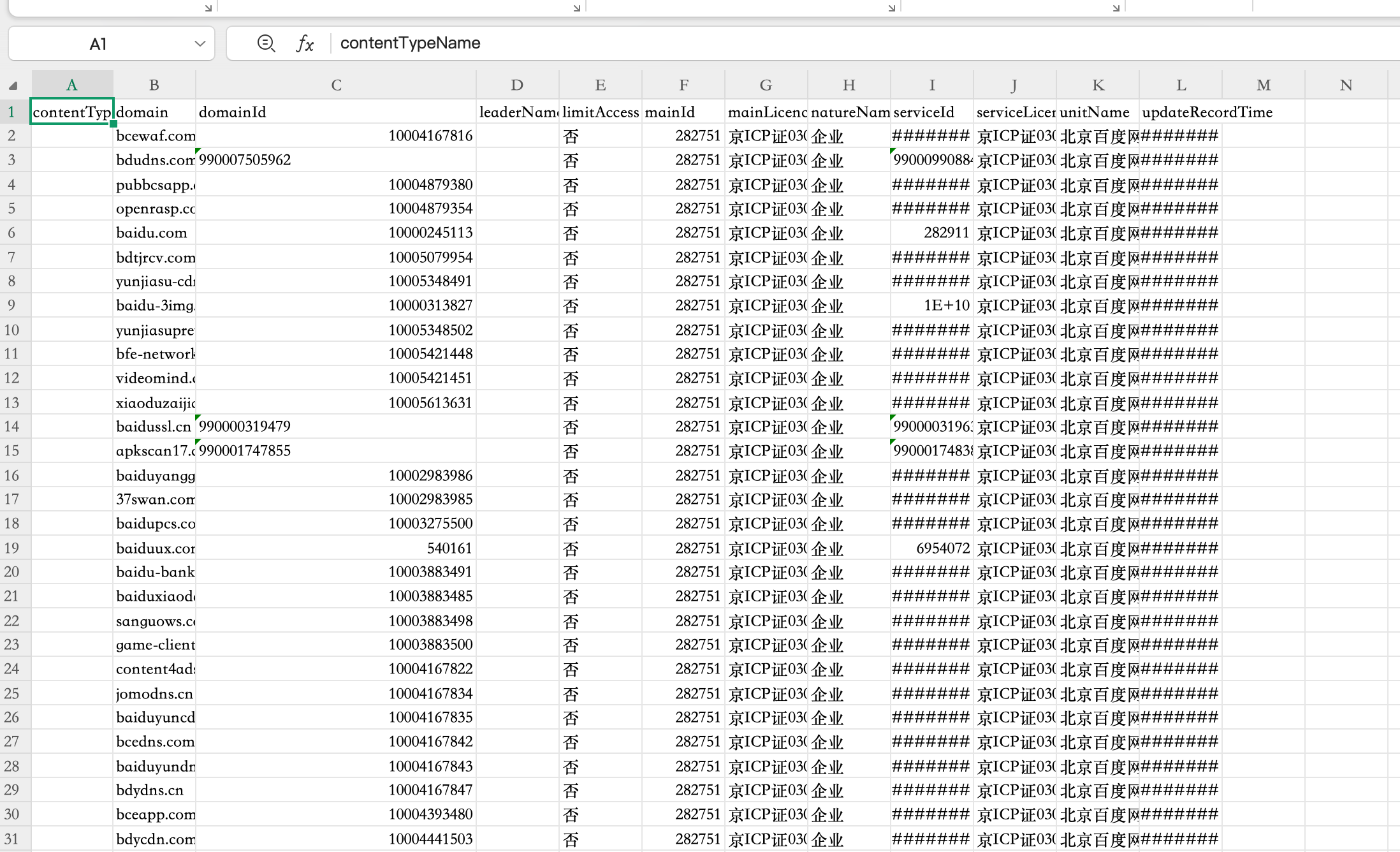
查看一下这个文件
最后
你说现在接入了有什么用呢,我目前也不知道具体有啥用,不过针对复杂的环境可能也有一丝用吧,好了下课!
